

الفصل : 12
الجزء : 2
العنوان : ال Redundancy في Windows Server 2022

كيف يعمل الفشل التلقائي (Failover)؟
بمجرد تكوين الكلستر الفشل التلقائي (failover clustering)، تظل العقد المتعددة في تواصل مستمر مع بعضها البعض. بهذه الطريقة، عندما تتعطل إحدى العقد، تكون العقد الأخرى على علم بذلك فوراً ويمكنها تحويل الخدمات إلى عقدة أخرى لإعادة تشغيلها. يستخدم الفشل التلقائي السجل (registry) لتتبع العديد من الإعدادات الخاصة بكل عقدة. يتم الحفاظ على تزامن هذه المعرفات عبر العقد، وعندما تتعطل إحداها، يتم نشر الإعدادات الضرورية على الخوادم الأخرى وتُبلغ العقدة التالية في الكلستر بتشغيل التطبيقات، VMs، أو الأحمال التي كانت تستضيفها العقدة الأساسية التي تعطلّت. قد يكون هناك تأخير بسيط في الخدمات بينما يتم تشغيل المكونات على العقدة الجديدة، لكن هذه العملية كلها مؤتمتة وتتم بدون تدخل، مما يبقي فترات التوقف في الحد الأدنى.
عندما تحتاج إلى نقل الخدمات من عقدة إلى أخرى كحدث مخطط له، مثل التحديثات أو الصيانة، هناك طريقة أفضل هنا. من خلال عملية تُعرف بالترحيل الحي (live migration)، يمكنك تحويل المسؤوليات إلى عقدة ثانوية بدون أي توقف. بهذه الطريقة، يمكنك إخراج العقد من الكلستر للصيانة أو لتطبيق التحديثات الأمنية، أو لأي سبب كان، دون التأثير على المستخدمين أو وقت تشغيل النظام بأي شكل. الترحيل الحي مفيد بشكل خاص لمجموعات Hyper-V، حيث غالباً ما تحتاج إلى اتخاذ قرارات يدوية حول أي عقدة تستضيف VMs حتى تتمكن من إنجاز العمل على العقدة الأخرى أو العقد.
في العديد من الكلسترات، هناك فكرة الكوورم (quorum). هذا يعني أنه إذا انقسم الكلستر، على سبيل المثال، إذا تعطلت عقدة أو إذا كانت هناك عدة عقد أصبحت فجأة غير متاحة بسبب انقطاع الشبكة من نوع ما، فإن منطق الكوورم يتولى تحديد أي جزء من الكلستر هو الجزء الذي لا يزال متصلاً بالإنترنت. إذا كان لديك كلستر كبير يمتد عبر شبكات فرعية متعددة داخل الشبكة، وحدث شيء ما على طبقة الشبكة التي تفصل عقد الكلستر عن بعضها البعض، كل ما تعرفه جانبي الكلستر هو أنهما لم يعودا يستطيعان التواصل مع أعضاء الكلستر الآخرين، وبالتالي سيفترض كلا الجانبين تلقائيًا أنهما يجب أن يتحملا المسؤولية عن أحمال الكلستر.
تحدد إعدادات الكوورم للكلستر عدد حالات فشل العقد التي يمكن أن تحدث قبل أن يكون الإجراء ضرورياً. من خلال معرفة الكلستر بأكمله لتكوين الكوورم، يمكنه المساعدة في تقديم إجابات على تلك الأسئلة حول أي جزء من الكلستر يجب أن يكون الأساسي في حال انقسام الكلستر. في العديد من الحالات، توفر الكلسترات الكوورم عن طريق الاعتماد على طرف ثالث، يُعرف بالشاهد (witness). كما يشير الاسم، هذا الشاهد يراقب حالة الكلستر ويساعد في اتخاذ قرارات حول متى وأين يصبح الفشل التلقائي ضرورياً.
هناك الكثير من المعلومات التي يمكن الحصول عليها وفهمها إذا كنت تنوي إنشاء كلسترات كبيرة بما يكفي لتكوين إعدادات الكوورم والشاهد. إذا كنت مهتمًا بمعرفة المزيد، يمكنك الاطلاع على [الرابط](https://docs.microsoft.com/en-us/windows-server/storage/storage-spaces/understand-quorum).
إعداد كلستر الفشل التلقائي (Failover Cluster)
سوف نقضي بضع دقائق لإعداد كلستر صغير من الخوادم حتى تتمكن من رؤية أدوات الإدارة والأماكن التي يجب زيارتها لتحقيق ذلك. لقد قمت الآن بإزالة جميع إعدادات NLB على خوادم WEB1 وWEB2 التي أعددناها سابقاً حتى تصبح مجرد خوادم ويب بسيطة في الوقت الحالي، مرة أخرى، بدون أي تكرار بينها. دعونا نعد أول كلستر فشل تلقائي ونضيف كلا هذين الخادمين إلى ذلك الكلستر.
بناء الخوادم
لدينا خادمان يعملان بالفعل بنظام Windows Server 2022 مثبت. لم يتم تكوين أي شيء خاص على هذه الخوادم، ولكنني قمت بإضافة دور File Server إلى كليهما لأنه في النهاية، سأستخدمها ككلستر لخوادم الملفات. النقطة الرئيسية هنا هي أنه يجب أن تكون الخوادم متطابقة قدر الإمكان، مع الأدوار المثبتة بالفعل التي تنوي استخدامها داخل الكلستر.
ملاحظة أخرى خلال مرحلة البناء: إذا أمكن، من الأفضل في الكلسترات أن تكون الخوادم الأعضاء في نفس الكلستر موجودة ضمن نفس الوحدة التنظيمية (OU) في Active Directory (AD). السبب في ذلك هو ذو شقين: أولاً، يضمن ذلك تطبيق نفس GPOs على مجموعة الخوادم، في محاولة لجعل تكويناتها متطابقة قدر الإمكان. ثانياً، خلال إنشاء الكلستر، سيتم إنشاء بعض الكائنات الجديدة تلقائيًا وإنشاؤها في AD، وعندما تكون الخوادم الأعضاء موجودة في نفس الوحدة التنظيمية، سيتم إنشاء هذه الكائنات الجديدة في تلك الوحدة أيضًا. من الشائع جدًا مع الكلسترات العاملة أن تكون جميع الكائنات ذات الصلة في AD جزءًا من نفس الوحدة التنظيمية، وأن تكون تلك الوحدة مخصصة لهذا الكلستر.
تثبيت الميزة
الآن بعد أن أصبحت خوادمنا متصلة وتعمل، نريد تثبيت قدرات الـ clustering على كل منها. Failover Clustering هو ميزة داخل Windows Server، لذلك قم بفتح معالج إضافة الأدوار والميزات وقم بإضافته إلى جميع العقد في الكتلة لديك.
تشغيل Failover Cluster Manager
كما هو الحال مع معظم الأدوار أو الميزات التي يمكن تثبيتها على Windows Server 2022، ستجد وحدة إدارة لها داخل قائمة Tools في Server Manager بمجرد تنفيذها. إذا نظرت إلى الداخل على WEB1 الآن، ستجد قائمة جديدة لـ Failover Cluster Manager متاحة لك لتضغط عليها. سأفتح هذه الأداة وأبدأ في تكوين الكتلة الأولى لي من خلال واجهة الإدارة هذه.

تشغيل التحقق من الكتلة
الآن بعد أن نحن داخل Failover Cluster Manager، ستلاحظ قائمة بالمهام المتاحة للتشغيل تحت قسم Management في وحدة التحكم، بالقرب من منتصف الشاشة.

قبل أن نتمكن من تكوين الكتلة نفسها أو إضافة أي عقد خادم إليها، يجب علينا أولاً التحقق من تكوين أجهزتنا. يعتبر الـ failover clustering مجموعة معقدة من التقنيات، وهناك العديد من الأماكن حيث يمكن أن تؤدي الأخطاء في التكوين أو التناقضات إلى إحداث خلل في الكتلة بأكملها. الغرض من إعداد الكتلة هو بالطبع من أجل الموثوقية والتكرار، ولكن حتى خطأ بسيط في تكوين خوادم الأعضاء قد يتسبب في مشكلات كبيرة تجعل فشل العقدة لا يؤدي إلى الاسترداد التلقائي، مما يلغي الغرض من الكتلة في المقام الأول. لضمان أن جميع النقاط تم مراجعتها، هناك بعض فحوصات التحقق الشاملة المدمجة في Failover Cluster Manager، مثل محلل أفضل الممارسات المدمج. يمكن تشغيل هذه الفحوصات في أي وقت – قبل بناء الكتلة أو بعد تشغيلها في الإنتاج لسنوات. في الواقع، إذا اضطررت في أي وقت لفتح قضية دعم مع Microsoft، فمن المحتمل أن يكون أول ما سيطلبون منك القيام به هو تشغيل أدوات Validate Configuration والسماح لهم بمراجعة المخرجات.
لبدء عملية التحقق، اضغط على رابط Validate Configuration... نحن الآن في معالج يسمح لنا بتحديد أجزاء تقنية الكتلة التي نرغب في التحقق منها. مرة أخرى، يجب علينا أن نفكر بطريقة إدارة مركزية لـ Microsoft وندرك أن هذا المعالج لا يعرف أو يهتم بأنه يعمل على أحد الخوادم الأعضاء التي ننوي أن تكون جزءاً من الكتلة. يجب علينا تحديد كل من عقد الخادم التي نرغب في فحصها من أجل التحقق، لذا في حالتي، سأخبره أنني أريد التحقق من الخوادم WEB1 و WEB2.
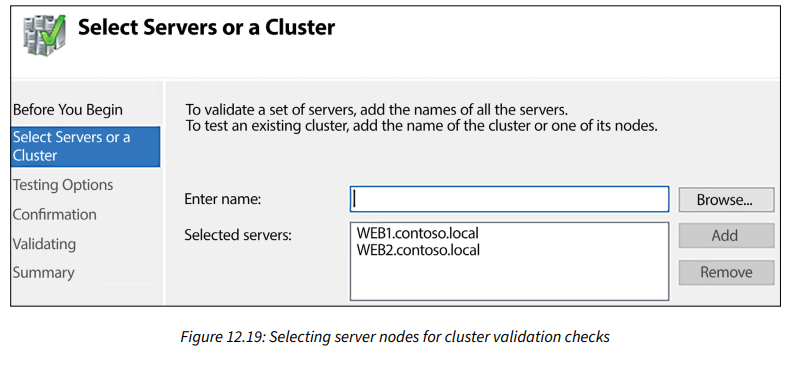
تسمح لك شاشة خيارات الاختبار باختيار خيار Run only tests I select ومن ثم ستكون قادرًا على تشغيل اختبارات تحقق معينة فقط. عموماً، عند إعداد كتلة جديدة، تريد تشغيل جميع الاختبارات للتأكد من أن كل شيء يعمل بشكل صحيح. في نظام الإنتاج، قد تختار تقليل عدد الاختبارات التي تُشغل. هذا ينطبق بشكل خاص على الاختبارات ضد التخزين، حيث يمكن أن تؤدي هذه الاختبارات فعلياً إلى تعطيل الكتلة مؤقتاً أثناء تشغيل الاختبارات، ولا ترغب في التداخل مع خدمات الإنتاج عبر الإنترنت إذا لم تكن تعمل ضمن نافذة صيانة مخطط لها.

لأنني أقوم بإعداد كتلة جديدة، سأدع جميع الاختبارات تعمل. لذلك سأترك الخيار الموصى به محددًا، Run all tests (recommended)، وأستمر.

بمجرد اكتمال الاختبارات، سترى ملخصًا لنتائجها. يمكنك الضغط على زر View Report... لرؤية الكثير من التفاصيل حول كل شيء تم تشغيله. تذكر أن هناك ثلاث مستويات من النجاح/الفشل. الأخضر جيد والأحمر سيء، لكن الأصفر يشير إلى أنه سيعمل لكنك لا تتبع أفضل الممارسات. على سبيل المثال، لدي فقط NIC واحد في كل من خوادمي؛ يعترف المعالج بذلك، ولجعل إعداد الكتلة لدي متكرراً بشكل كامل، يجب أن يكون لدي على الأقل اثنين. سيترك هذا ويمر ويستمر في العمل، لكنه يحذرني بأنه يمكنني تحسين هذه الكتلة أكثر بإضافة NIC ثانية لكل عقدة.
إذا احتجت في أي وقت إلى إعادة فتح هذا التقرير أو أخذ نسخة منه من الخادم للحفظ، فستجده موجودًا على الخادم الذي قمت بتشغيل الاختبارات عليه، داخل
C:\Windows\Cluster\Reports.

تذكر، يمكنك إعادة تشغيل عمليات التحقق في أي وقت لاختبار تكوينك باستخدام مهمة Validate Configuration... داخل Failover Cluster Manager.
تشغيل معالج إنشاء الكتلة
قد تستغرق مرحلة التحقق وقتًا إذا كان لديك نتائج متعددة تحتاج إلى إصلاح قبل أن تتمكن من المتابعة. ولكن بمجرد عودة فحص التحقق الخاص بك نظيفًا، تكون جاهزًا لبناء الكتلة. للقيام بذلك، اضغط على الإجراء التالي المتاح لدينا في وحدة التحكم الخاصة بـ Failover Cluster Manager: Create Cluster...
مرة أخرى، يجب علينا أولاً تحديد أي الخوادم نرغب في أن تكون جزءًا من هذه الكتلة الجديدة، لذلك سأدخل خوادم WEB1 و WEB2. بعد ذلك، ليس لدينا الكثير من المعلومات لإدخالها حول إعداد الكتلة، ولكن هناك قطعة أساسية جدًا من المعلومات على شاشة Access Point for Administering the Cluster. هنا، تحدد الاسم الفريد الذي سيستخدمه الكتلة ويشاركه بين خوادم الأعضاء. يُعرف هذا باسم Cluster Name Object (CNO)، وبعد إكمال تكوين الكتلة الخاصة بك، سترى هذا الاسم يظهر ككائن داخل AD.
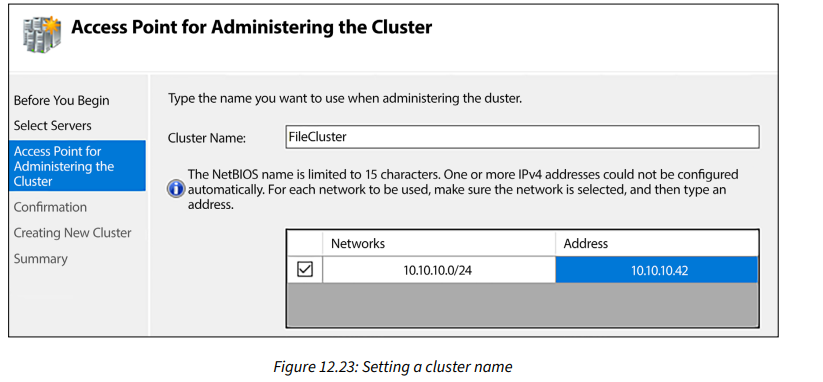
بعد الانتهاء من المعالج، يمكنك رؤية الكتلة الجديدة داخل واجهة Failover Cluster Manager ويمكنك التعمق في وظائف أكثر تحديداً داخل تلك الكتلة. هناك إجراءات إضافية لأشياء مثل Configure Role...، والتي ستكون مهمة لإعداد الوظيفة الفعلية التي ستقوم بها هذه الكتلة، و Add Node...، والتي تكون مكانك لإضافة المزيد من خوادم الأعضاء في هذه الكتلة في المستقبل.
تحسينات التجميع في Windows Server 2022
كانت ميزة التجميع موجودة منذ فترة طويلة، وكل إصدار جديد من Windows Server يأتي مع بعض التحسينات والميزات الجديدة، ولكن غالبًا ما تمر دون ملاحظة. كانت هناك بعض التغييرات الجيدة في 2019، وتبعها المزيد في 2022. تم تضمين بعض هذه التحسينات في Server 2022 مباشرة من Azure Stack HCI، مما يجلب قدرات السحابة مرة أخرى إلى مراكز البيانات لدينا. دعونا نستعرض بعضًا منها لترى الطرق التي تواصل بها Microsoft التزامها بتحسين موثوقية مركز البيانات لدينا.
ال AutoSites
العديد من المسؤولين لا يهتمون حتى بخدمات Active Directory Sites and Services لأن العديد منهم لديهم موقع واحد فقط للتعامل معه، ولكن حتى إذا كان لديك مواقع فيزيائية متعددة تشمل الخوادم، فإنه غالبًا ما يكون صحيحًا أن معظم تكنولوجيا Windows Server ستعمل بشكل جيد حتى لو تركت جميع خوادمك موصولة بالموقع الافتراضي لـ AD. Failover clustering هو أحد الأدوار التي يمكنها الآن الاستفادة من المواقع المهيأة بشكل صحيح في AD. إذا قمت بتكوين مواقعك الفيزيائية وتأكدت من أن عقد الكتلة الاحتياطية مخصصة للمواقع المناسبة في AD، فإن الـ failover clustering سيقوم تلقائيًا بإنشاء site fault domains وفقًا لأسماء مواقعك، ووضع عقد الـ failover في المواقع المناسبة.
ال Clustering Affinity
قبل Windows Server 2022، كان لدى failover clustering القدرة على تطبيق قواعد AntiAffinity. AntiAffinity هي طريقة لتحديد الأدوار (مثل VMs) داخل كتلة احتياطية وإنشاء قواعد لهذه الأدوار لإبعادها عن بعضها البعض. على سبيل المثال، إذا كنت ترغب في التأكد من أن خادمين جزءًا من نفس الكتلة الاحتياطية يبقيان منفصلين ويعملان على خوادم Hyper-V مختلفة.
ما هو الجديد في 2022 هو أنه يمكننا الآن تكوين قواعد Affinity بالإضافة إلى قواعد AntiAffinity. تعمل قواعد Affinity بنفس الطريقة ولكن بالعكس. إنه نهج أكثر منطقية لتجميع الأدوار أو العقد معًا، عن طريق تحديد أنك تريد بقاء بعض الأدوار معًا داخل نفس المضيف أو الموقع، بدلاً من الحاجة إلى التفكير بشكل عكسي وتحديد أيها يجب إبعادها عن بعضها البعض.
تحسينات على التخزين المشفر بواسطة BitLocker في الكتلة
أنت تعلم أن خوادم الكتلة الاحتياطية يجب أن تشارك نفس التخزين لتكون الكتلة ناجحة، وربما تكون على دراية بأن BitLocker هو وسيلة شائعة جدًا لتشفير وحماية أي وحدة تخزين تستند إلى Windows. في الإصدارات السابقة من Windows Server، كان تشفير وحدة تخزين الكتلة المشتركة باستخدام BitLocker مخاطرة، حيث كان يجب دائمًا سحب مفتاح BitLocker مباشرة من Active Directory للسماح بالوصول إلى ذلك التخزين ونجاح تحميل الوحدة. إذا لم يكن هناك Domain Controller متاح، فقد يؤدي ذلك إلى فشل مورد الكتلة في البدء. في Server 2022، هناك الآن حماية مفتاح إضافية خاصة بالكتلة نفسها. أثناء التمهيد أو فك التشفير لتلك الوحدة، ستحاول دائمًا الوصول إلى Active Directory للحصول على معلومات الفتح الحقيقية. إذا كان AD غير متاح، يمكن للكتلة أن تنجح باستخدام مفتاح الفتح المخزن محليًا لتحميل الوحدة.
تحسينات قديمة
قليلاً (لكنها لا تزال رائعة)
من الصعب دائمًا تحديد ما إذا كانت "الإصدارات الجديدة" التي جاءت مع إصدار سابق من Windows Server يجب أن تبقى في كتاب محدث، ولكن أعتقد أن فهم أي شيء يتطلب معرفة من أين جاء. إليك بعض المكونات الجديدة نسبيًا للتجميع التي جاءت إلينا عبر Windows Server 2019، ولا تزال تقنية مفيدة حتى اليوم.
ال True two-node clusters with USB witnesses
عند تكوين نظام quorum لكتلة احتياطية، قبل Server 2019، كانت كتلة ذات عقدتين تتطلب ثلاث خوادم، لأن الشاهد للنظام يجب أن يكون على مشاركة شاهد من نوع ما، عادةً على خادم ملفات منفصل.
بدءًا من 2019، يمكن أن يكون هذا الشاهد الآن عبارة عن محرك أقراص USB بسيط، ولا يجب حتى أن يكون متصلاً بخادم Windows! هناك العديد من قطع المعدات الشبكية (المحولات، أجهزة التوجيه، وما إلى ذلك) التي يمكن أن تقبل وسائط التخزين المبنية على USB، ومحرك USB متصل بمثل هذا الجهاز الشبكي يكفي الآن لتلبية متطلبات شاهد الكتلة. هذه نقطة إيجابية لتحسين التجميع في البيئات الصغيرة.
أمان أعلى للكتل
تم إجراء عدد من التحسينات الأمنية على الـ failover clustering في Windows Server 2019. كانت الإصدارات السابقة تعتمد على New Technology LAN Manager (NTLM) لمصادقة حركة المرور داخل الكتلة، ولكن العديد من الشركات تتخذ خطوات استباقية لتعطيل استخدام NTLM (على الأقل الإصدارات المبكرة) داخل شبكاتها. يمكن للـ failover clustering الآن إجراء اتصالات داخل الكتلة باستخدام Kerberos والشهادات للتحقق من صحة حركة المرور الشبكية، مما يلغي الحاجة إلى NTLM. فحص أمني/استقرارية آخر تم تنفيذه عند إنشاء شاهد مشاركة ملف الكتلة هو حجب الشهود المخزنة داخل DFS. لم يكن إنشاء شاهد داخل مشاركة DFS مدعومًا أبدًا، لكن وحدة التحكم كانت تسمح بذلك سابقًا، مما يعني أن بعض الشركات قامت بذلك بالضبط، ودفعوا الثمن لأن هذا يمكن أن يسبب مشكلات في استقرار الكتلة. تم تحديث أدوات إدارة الكتلة للتحقق من وجود مساحة اسم DFS عند إنشاء شاهد ولن تسمح بذلك بعد الآن.
ال Multi-site clustering
هل يمكنني تكوين failover clustering عبر الشبكات الفرعية؟ بعبارة أخرى، إذا كان لدي مركز بيانات رئيسي واستأجرت أيضًا مساحة من CoLo أسفل الطريق، أو كان لدي مركز بيانات آخر في جميع أنحاء البلاد، فهل هناك خيارات لي لإعداد التجميع بين العقد التي هي فعليًا منفصلة؟ الإجابة السريعة والبسيطة هنا هي: نعم، لا يهتم الـ failover clustering! بنفس السهولة كما لو كانت عقد الخادم تلك جالسة بجوار بعضها البعض، يمكن للتجميع الاستفادة من مواقع متعددة يستضيف كل منها عقد مجمعة وتحريك الخدمات ذهابًا وإيابًا عبر هذه المواقع.
ال Cross-domain or workgroup clustering
تاريخيًا، كنا قادرين فقط على إنشاء failover clustering بين العقد التي كانت منضمة إلى نفس النطاق. قدم Windows Server 2016 القدرة على الخروج من هذا القيد، ويمكننا حتى بناء كتلة بدون وجود Active Directory في الصورة على الإطلاق. في Server 2016 و 2019، يمكنك بالطبع إنشاء كتل حيث تكون جميع العقد منضمة إلى نفس النطاق، ونتوقع أن يكون هذا هو الغالبية العظمى من التثبيتات الموجودة هناك. ومع ذلك، إذا كان لديك خوادم منضمة إلى نطاقات مختلفة، يمكنك الآن إنشاء التجميع بين تلك العقد. علاوة على ذلك، يمكن الآن أن تكون الخوادم الأعضاء في الكتلة أعضاء في مجموعة عمل ولا تحتاج إلى الانضمام إلى نطاق على الإطلاق.
في حين أن هذا يوسع القدرات المتاحة للتجميع، فإنه يأتي أيضًا مع بعض القيود. عند استخدام الكتل المتعددة النطاقات أو كتل مجموعة العمل، ستكون محدودًا بـ PowerShell كواجهة إدارة الكتلة الخاصة بك. إذا كنت معتادًا على التفاعل مع الكتل الخاصة بك من أحد أدوات GUI، فستحتاج إلى تعديل تفكيرك في هذا الأمر. ستحتاج أيضًا إلى إنشاء حساب مستخدم محلي يمكن استخدامه بواسطة التجميع وتوفيره لكل عقدة في الكتلة، ويجب أن يكون لهذا الحساب المستخدم حقوق إدارية على تلك الخوادم.
ال Migrating cross-domain clusters
على الرغم من أن إنشاء التجمعات عبر عدة مجالات (domains) كان ممكنًا منذ بضع سنوات، إلا أن نقل التجمعات من مجال Active Directory إلى آخر لم يكن خيارًا متاحًا. بدأ من Windows Server 2019، تغير هذا الوضع. لدينا الآن مرونة أكبر في التجمعات متعددة المجالات، بما في ذلك القدرة على نقل التجمعات بين تلك المجالات. هذه القدرة ستساعد المسؤولين في التعامل مع عمليات الاستحواذ على الشركات ومشاريع دمج المجالات.
تحديث نظام التشغيل للتجمع بشكل مستمر
هذه القدرة الجديدة التي أُتيحت لنا في 2016 تحمل اسمًا غريبًا لكنها ميزة رائعة. تم تصميمها لمساعدة أولئك الذين استخدموا التجمع الفاشل لفترة طويلة على تحسين بيئتهم. إذا كنت تشغل حاليًا تجمعًا يعمل بنظام Windows Server 2012 R2، فهذا شيء يجب النظر فيه بالتأكيد.
يمكنك ترقية أنظمة تشغيل عقد التجمع من Server 2012 R2 إلى Server 2016، ثم إلى Server 2019، ومرة أخرى إلى Server 2022، كل ذلك بدون توقف العمل. ليس هناك حاجة لإيقاف أي من الخدمات على أحمال عمل Hyper-V أو SOFS التي تستخدم التجمع؛ ببساطة تستخدم عملية الترقية المستمرة وجميع عقد التجمع ستعمل على الإصدار الأحدث من Windows Server. يبقى التجمع متصلًا ونشطًا، ولا أحد يعرف حتى أن الأمر حدث. باستثنائك بالطبع.
هذا يختلف تمامًا عن عملية الترقية السابقة حيث، من أجل ترقية التجمع إلى Server 2012 R2، كنت بحاجة إلى إيقاف التجمع، وإدخال عقد خوادم جديدة تعمل بنظام 2012 R2، ثم إعادة إنشاء التجمع. كان هناك الكثير من وقت التوقف والصداع المرتبط بهذه الترقيات.
الحيلة التي تجعل هذه الترقية السلسة ممكنة هي أن التجمع نفسه يبقى يعمل عند مستوى الوظائف الخاص بـ 2012 R2 حتى تصدر أمرًا لتغييره إلى مستوى الوظائف الخاص بـ Server 2016. حتى تصدر هذا الأمر، يعمل التجمع على المستوى الوظيفي الأقدم، حتى على العقد الجديدة التي تقدمها، والتي تعمل بنظام التشغيل Server 2016. أثناء ترقية العقد واحدة تلو الأخرى، تبقى العقد الأخرى التي لا تزال نشطة في التجمع متصلة وتستمر في خدمة المستخدمين والتطبيقات، لذلك كل الأنظمة تعمل كالمعتاد من منظور أحمال العمل. أثناء تقديم خوادم جديدة تعمل بنظام Server 2016 إلى التجمع، تبدأ في خدمة أحمال العمل مثل خوادم 2012 R2، ولكن بمستوى وظيفي 2012 R2. يُشار إلى هذا بوضعية مختلطة. هذا يمكن من إنزال آخر صندوق 2012 R2، تغييره إلى 2016، وإعادة تقديمه، دون أن يعرف أحد. ثم، بمجرد اكتمال جميع ترقيات نظام التشغيل، تصدر أمر PowerShell Update-ClusterFunctionalLevel لتغيير المستوى الوظيفي، وتكون لديك تجمع Windows Server 2016 (أو 2019 أو أيًا كان) الذي تمت ترقيته بسلاسة بدون أي وقت توقف.
ال Storage Replica (SR)
SR هو طريقة حديثة لمزامنة البيانات بين الخوادم. هي تقنية تكرار البيانات توفر القدرة على تكرار البيانات على مستوى الكتل بين الخوادم، حتى عبر مواقع فيزيائية مختلفة. SR هو نوع من التكرار الذي لم نره في منصة Microsoft قبل Windows Server 2016؛ في الماضي، كان علينا الاعتماد على أدوات الجهات الخارجية لهذه القدرة. SR أيضًا مهم للنقاش على أعقاب التجمع الفاشل لأنه هو العنصر السري الذي يمكن من حدوث التجمع الفاشل عبر المواقع المتعددة.
عندما ترغب في استضافة عقد التجمع في مواقع فيزيائية متعددة، تحتاج إلى طريقة للتأكد من أن البيانات المستخدمة من قبل تلك العقد محدثة بشكل مستمر، حتى يكون الفشل الفعلي ممكنًا. يتم توفير هذا التدفق من البيانات بواسطة SR.
أحد النقاط الرائعة حول SR هو أنه يسمح أخيرًا بحل يعتمد على بائع واحد، وهو Microsoft بالطبع، لتقديم التكنولوجيا والبرمجيات من النهاية إلى النهاية للتخزين والتجمع. كما أنه مستقل عن العتاد، مما يمنحك القدرة على استخدام تفضيلاتك الخاصة لوسائط التخزين. تم تصميم SR ليكون مدمجًا بإحكام وأحد التقنيات الداعمة لبيئة التجمع الفاشل الصلبة. في الواقع، واجهة الإدارة الرسومية لـ SR موجودة داخل برنامج Failover Cluster Manager – ولكن بالطبع يمكن تهيئتها أيضًا عبر PowerShell – لذا تأكد من إلقاء نظرة على التجمع الفاشل وSR كقصة متكاملة لبيئتك.
الآن، SR متاح داخل إصدارات Server 2019 و2022 Standard! (في السابق، كان يتطلب الإصدار Datacenter، مما كان عائقًا لبعض التطبيقات). إدارة SR متاحة أيضًا الآن داخل Windows Admin Center (WAC) الجديد. لنقم بإنشاء بيئة Storage Replica، حتى تتمكن من رؤية مدى سرعة وسهولة إنشاء التكرار التخزيني.
النهاية
نكون هنا انتهينا من الجزء 2 من الفصل 12 تماما من شهادة MCSA المقدمة من Microsoft الأن نغوص في الأعماق
و لا بد وانت تقرا ان تكون مركز جيدا لكل معلومة ومعك ورقة وقلم , لانك بالتاكيد ستحتاجها
واذا واجهتك اي مشكلة في الفهم او ما شابه , يمكنك على الفور الذهاب الى المجتمع الخاص بنا في Telegram للمناقشة والتواصل معنا من هنا
او اذا واجهتك مشكلة في الموقع او تريد اجابة سريعة يمكنك الذهاب الى اخر صفحة في الموقع ستجد صفحة اتصل بنا موجودة يمكنك ارسالة لنا مشكلتك , وسيتم الرد عليها بسرعة جدا ان شاء الله
ويمكنك الأنضمام الى المجتمع Hidden Lock بالكامل مع جميع قنواته للأستفادة في اخر الأخبار في عالم التقنية وايضا الكتب بالمجان والكورسات والمقالات من خلال الرابط التالي لمجموعة القنوات من هنا
يمكنك ايضا متابعتنا في منصات X او Twitter سابقا , لمشاهدة الاخبار والمقالات السريعة والمهمة من
وفقط كان معكم Sparrow اتمنى ان تدعوا لي وتتذكروني في الخير دوما
